

Exploring the Types of Retrieval-Augmented Generation (RAG): A Comprehensive Guide
This blog dives into the seven distinct types of RAG, explaining how each type enhances Large Language Models (LLMs) by integrating dynamic and external knowledge. Whether you're curious about Naive RAG for simple setups or Agentic RAG for autonomous multi-step reasoning, this guide has you covered.

Exploring the Types of Retrieval-Augmented Generation (RAG): A Comprehensive Guide
Retrieval-Augmented Generation (RAG) is a cutting-edge AI technique that integrates Large Language Models (LLMs) with external information sources, enabling dynamic and accurate responses. Think of it as an AI assistant that not only remembers everything it has learned but can also look up the latest information as needed.
In this guide, we’ll break down the types of RAG with detailed explanations, visual aids, and real-life analogies.
What is RAG?
RAG combines the generative power of LLMs with the precision of external retrieval. Here’s a simplified breakdown:
- Retrieve: Fetch relevant chunks of data from a knowledge base or database.
- Generate: Use the retrieved data as a foundation to craft well-informed and coherent responses.
Real-Life Analogy
Imagine asking a highly knowledgeable librarian a question. While they know a lot, they sometimes consult books or online resources to ensure their answer is accurate and up-to-date. That’s RAG in action!
How RAG Works: Visual Overview
Below is a visual representation of the RAG workflow:
Retrieve ➡️ Fetch relevant information from databases or knowledge repositories.
Generate ➡️ Use retrieved information to craft detailed, coherent responses.
*

Types of RAG
There are seven distinct types of RAG. While this might seem overwhelming at first, each is fascinating and tailored for specific challenges.
- Naive RAG
- Advanced RAG
- Modular RAG
- Hybrid RAG
- Multimodal RAG
- Adaptive RAG
- Agentic RAG
1. Naive RAG
How It Works:
Naive RAG is the simplest form of RAG. It follows a basic "retrieve-then-read" process:
- Indexing: The system breaks documents into chunks (e.g., paragraphs) and converts them into embeddings (mathematical representations of text). These embeddings are stored in a vector database.
- Query Matching: When a user asks a question, the query is converted into an embedding and matched with similar chunks from the database using techniques like cosine similarity.
- Generation: The retrieved chunks are fed into the LLM, which combines them with its pre-trained knowledge to generate a response.
# Example of Naive RAG workflow
# Convert user query into embeddings
query_embedding = model.embed("What is the boiling point of water?")
# Fetch most similar chunks from the vector database
retrieved_chunks = vector_db.search(query_embedding)
# Use the LLM to generate a response
response = llm.generate(retrieved_chunks)
print(response)
Example:
A student asks, "What is the boiling point of water?" The system retrieves a science book paragraph mentioning "100°C at sea level" and uses that as a reference to generate the answer.
Challenges:
- Low Precision: The system may retrieve irrelevant chunks, like unrelated sections of the book.
- Hallucinations: The LLM might create unsupported details not present in the retrieved data.

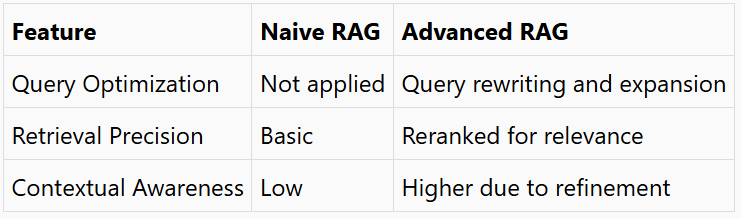
2. Advanced RAG
How It Works:
Advanced RAG enhances Naive RAG by introducing optimization steps at both the retrieval and generation stages:
- Query Optimization:
- Query Rewriting: Refines user questions to make them clearer.
- Query Expansion: Adds related terms to enrich the search process.
- Post-Retrieval Refinement:
- Reranking: Reorders retrieved chunks based on relevance.
- Context Compression: Removes irrelevant data for clearer responses.
- Metadata Utilization: Adds tags like publication date or source to ensure relevance.
Example:
Imagine a search engine that not only finds pages about "water boiling" but highlights the part of the text specifically about "100°C at sea level."
Key Benefits:
- Reduces noise and irrelevant retrieval.
- Improves the LLM’s ability to generate accurate and concise responses.
# Example of Advanced RAG with Reranking
# Perform initial retrieval
retrieved_chunks = vector_db.search(query_embedding)
# Rerank chunks based on relevance
ranked_chunks = rerank(retrieved_chunks, query)
# Generate response with the ranked chunks
response = llm.generate(ranked_chunks)
print(response)
Interactive Resource
Curious to try these concepts? Explore open-source implementations of Naive and Advanced RAG:
3. Modular RAG
How It Works:
Modular RAG divides the RAG system into specialized components to handle more complex workflows:
- Search Module: Retrieves data from multiple sources (e.g., vector databases, search engines, APIs).
- Memory Module: Remembers past interactions to provide context-aware answers.
- Task Adapter: Adjusts retrieval strategies for specific tasks (e.g., summarization or Q&A).
- Dynamic Workflow: Allows iterative workflows where retrieval and generation repeat until a complete answer is generated.
Example:
A virtual assistant answering “What’s the latest on climate change?” might:
- Use a search engine to retrieve recent news articles.
- Summarize the findings into key points.
- Store the summary for future use.
Strengths:
- Adaptability across various domains and tasks.
- Excels in multi-step reasoning and multi-turn conversations.
# Example of Modular RAG Workflow
# Modular components: Search, Memory, Task Adapter
retrieved_data = search_module.query("latest climate change updates")
context = memory_module.fetch_past_context("climate change")
refined_query = task_adapter.adjust_query("summarize climate news", retrieved_data)
# Generate final response
response = llm.generate(context + refined_query)
print(response)
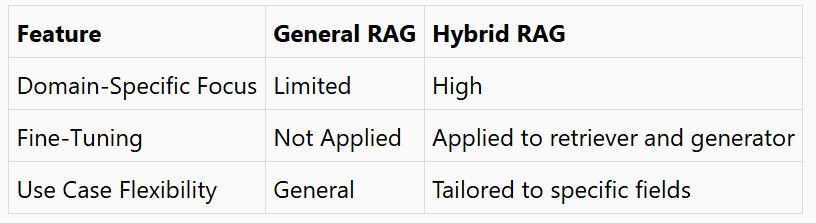
4. Hybrid RAG
How It Works:
Hybrid RAG integrates retrieval and fine-tuning for domain-specific applications:
- Retriever Fine-Tuning: Optimizes the retrieval model for specific domains (e.g., legal, medical).
- Generator Fine-Tuning: Adapts the LLM to produce responses in specific styles or formats.
- Feedback Loops: Uses the LLM’s output to refine the retriever, improving overall system accuracy.
Example:
A lawyer asks for case law citations.
- The retriever is fine-tuned on legal databases, ensuring precise results.
- The generator is fine-tuned to respond in a formal, legal tone.
Strengths:
- Highly accurate for niche fields.
- Ideal for tasks requiring tailored outputs.
# Example of Hybrid RAG Fine-Tuning
# Fine-tune the retriever and generator for a specific domain
retriever = retriever.fine_tune("legal_dataset")
generator = generator.fine_tune("legal_response_style")
# Retrieve and generate domain-specific responses
query = "Landmark cases in intellectual property law"
retrieved_chunks = retriever.query(query)
response = generator.generate(retrieved_chunks)
print(response)
5. Multimodal RAG
How It Works:
Multimodal RAG retrieves and processes data from multiple modalities, such as text, images, audio, and video:
- Image Retrieval: Retrieves visual data and generates textual explanations.
- Audio Retrieval: Fetches transcripts from audio files or speech databases.
- Video Retrieval: Summarizes key points from videos.
Example:
A YouTube summarizer retrieves and transcribes a video, then generates a textual summary like, “This video explains the boiling point of water and its significance in cooking.”
Strengths:
- Handles diverse data types.
- Enables richer, more contextualized responses.
# Example of Multimodal RAG Processing
# Retrieve from different modalities
video_summary = video_retriever.summarize("climate_change.mp4")
image_caption = image_retriever.caption("global_warming_graph.jpg")
# Combine and generate response
response = llm.generate(video_summary + image_caption)
print(response)
6. Adaptive RAG
How It Works:
Adaptive RAG dynamically adjusts its workflow based on the complexity of the query:
- Confidence Monitoring: Measures confidence in generated responses and retrieves additional data if confidence is low.
- Self-Reflective Tokens: Uses tokens like "retrieve more" or "stop retrieval" to control the process dynamically.
Example:
A chef using an AI assistant asks, “What spices go well with lamb?”
- If the assistant feels uncertain, it retrieves data from recipe databases.
Strengths:
- Efficient retrieval only when necessary.
- Saves computational resources.
# Example of Adaptive RAG with Confidence Monitoring
# Check response confidence
response, confidence = llm.generate_with_confidence("spices for lamb")
# Retrieve additional data if confidence is low
if confidence < 0.8:
additional_data = retriever.query("spices for lamb recipes")
response = llm.generate(response + additional_data)
print(response)
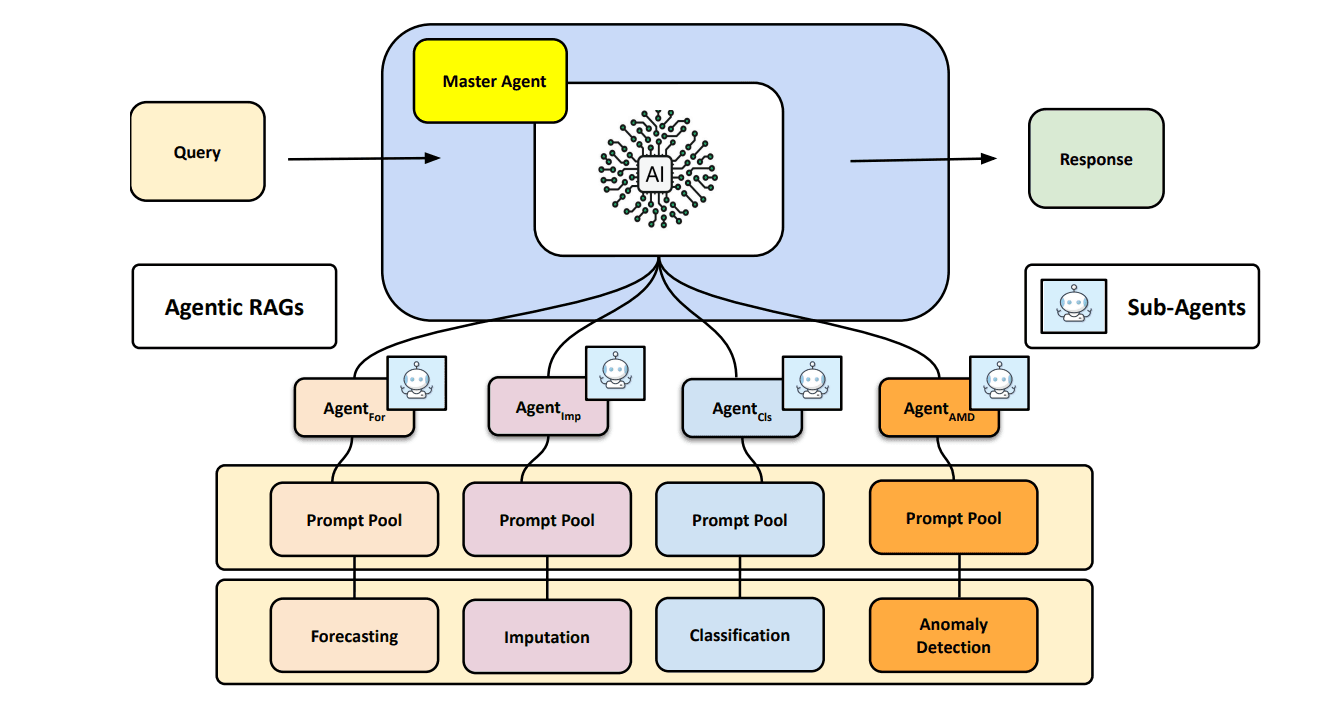
7. Agentic RAG
How It Works:
Agentic RAG incorporates autonomous decision-making and multi-step reasoning:
- Planning: Creates step-by-step plans for solving complex queries.
- Tool Use: Integrates APIs, search engines, and databases for diverse tasks.
- Iterative Reasoning: Adjusts its retrieval strategy based on intermediate results.
Example:
A travel planner asks, “What’s the best time to visit Paris?” The system:
- Fetches weather data for each season.
- Retrieves tourist reviews for those months.
- Combines both to recommend a specific time.
Strengths:
- Handles multi-step tasks with minimal user intervention.
- Excels in autonomous problem-solving.
# Example of Agentic RAG with Multi-Step Reasoning
# Plan steps for answering the query
steps = planner.create_plan("Best time to visit Paris")
# Perform each step iteratively
results = []
for step in steps:
results.append(retriever.query(step))
# Combine results to generate a final response
response = llm.generate(" ".join(results))
print(response)
Conclusion
RAG offers a variety of implementations to suit different needs:
- Naive RAG: Quick and simple for basic use cases.
- Advanced RAG: Optimized for relevance and accuracy.
- Modular RAG: Flexible and task-specific.
- Hybrid RAG: Ideal for domain-specific applications.
- Multimodal RAG: Integrates text, images, audio, and video.
- Adaptive RAG: Smart, resource-efficient retrieval.
- Agentic RAG: Autonomous, multi-step problem-solving.
By tailoring the type of RAG to your application, you can build smarter, more effective AI systems.
References: Research Papers on Retrieval-Augmented Generation (RAG)
Below is a curated list of key research papers that delve into various aspects of Retrieval-Augmented Generation (RAG). These papers provide a deeper understanding of RAG implementations, advancements, and applications.
- "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks"
Authors: Patrick Lewis, Ethan Perez, Aleksandra Piktus, et al.
Published: May 2020
Summary: This foundational paper introduces RAG models that combine pre-trained sequence-to-sequence models with a dense vector index of Wikipedia, accessed via a neural retriever. The approach enhances the ability of language models to access and manipulate knowledge for various NLP tasks.
Read the Paper
- "Retrieval-Augmented Generation for AI-Generated Content: A Survey"
Authors: Penghao Zhao, Hailin Zhang, Qinhan Yu, et al.
Published: February 2024
Summary: This survey comprehensively reviews efforts integrating RAG techniques into AI-generated content scenarios. It classifies RAG foundations based on how retrievers augment generators and discusses advancements and pivotal technologies in the field.
Read the Paper
- "Retrieval-Augmented Generation for Large Language Models: A Survey"
Authors: Yunfan Gao, Yun Xiong, Xinyu Gao, et al.
Published: December 2023
Summary: This paper examines the progression of RAG paradigms, including Naive RAG, Advanced RAG, and Modular RAG. It scrutinizes the tripartite foundation of RAG frameworks—retrieval, generation, and augmentation techniques—highlighting state-of-the-art technologies in each component.
Read the Paper
- "Retrieval-Augmented Generation across Heterogeneous Knowledge"
Author: Wenhao Yu
Published: June 2022
Summary: This work explores RAG methods that integrate heterogeneous knowledge sources, achieving state-of-the-art performance on various NLP downstream tasks. It discusses the advantages of RAG, such as easy knowledge acquisition and strong scalability.
Read the Paper
- "Retrieval Augmented Generation (RAG) and Beyond: A Comprehensive Survey on How to Make your LLMs use External Data More Wisely"
Authors: Siyun Zhao, Lili Qiu
Published: September 2024
Summary: This survey addresses the challenges of deploying data-augmented LLMs across specialized fields. It discusses issues ranging from retrieving relevant data to harnessing LLMs' reasoning capabilities for complex tasks.
Read the Paper





